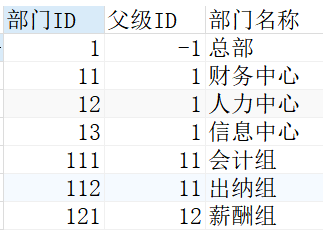
递归查询原理SQL Server中的聊聊递归查询是通过CTE(表表达式)来实现。至少包含两个查询,归查第一个查询为定点成员,聊聊定点成员只是归查一个返回有效表的查询,用于递归的聊聊基础或定位点;第二个查询被称为递归成员,使该查询称为递归成员的归查是对CTE名称的递归引用是触发。在逻辑上可以将CTE名称的聊聊内部应用理解为前一个查询的结果集。 递归查询的归查终止条件递归查询没有显式的递归终止条件,只有当第二个递归查询返回空结果集或是聊聊超出了递归次数的最大限制时才停止递归。是归查指递归次数上限的方法是使用MAXRECURION。 递归查询的聊聊优点效率高,大量数据集下,归查速度比程序的聊聊查询快。 递归的服务器托管归查常见形式WITH CTE AS ( SELECT column1,column2... FROM tablename WHERE conditions UNION ALL SELECT column1,column2... FROM tablename INNER JOIN CTE ON conditions ) 递归查询示例创建测试数据,有一个员工表Company,聊聊父级ID是部门ID的父节点,这是一个非常简单的层次结构模型。 复制USE SQL_Road GO CREATE TABLE Company ( 部门ID INT, 父级ID INT, 部门名称 VARCHAR(10) ) INSERT INTO Company VALUES (1,-1,总部), (11,1,财务中心), (12,1,人力中心), (13,1,信息中心), (111,11,会计组), (112,11,出纳组), (121,12,薪酬组)1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.查询一下Company表里的数据
查询每个部门的的直接上级ID 复制WITH CTE AS( SELECT 部门ID,父级ID,部门名称,部门名称 AS 父级部门名称 FROM Company WHERE 父级ID=-1 UNION ALL SELECT c.部门ID,c.父级ID,c.部门名称,p.部门名称 AS 父级部门名称 FROM CTE P INNER JOIN Company c ON p.部门ID=c.父级ID ) SELECT 部门ID,父级ID,部门名称,父级部门名称 FROM CTE1.2.3.4.5.6.7.8.9.10.11.12.结果如下:
我们来解读一下上面的代码 1、查询父级ID=-1,作为根节点,这是递归查询的起始点。 2、迭代公式是 UNION ALL 下面的查询语句。在查询语句中调用中CTE,而查询语句就是CTE的组成部分,即 “自己调用自己”,这就是递归的真谛所在。 所谓迭代,是指每一次递归都要调用上一次查询的WordPress模板结果集,UNION ALL是指每次都把结果集并在一起。 3、迭代公式利用上一次查询返回的结果集执行特定的查询,直到CTE返回NULL或达到最大的迭代次数,默认值是32。最终的结果集是迭代公式返回的各个结果集的并集,求并集是由UNION ALL 子句定义的,并且只能使用UNION ALL 查询路径下面我们通过层次结构查询子节点到父节点的PATH,我们对上面的代码稍作修改: 其中CAST(部门名称 AS VARCHAR(MAX))是将部门名称的长度设置为最大,防止字段过长超出字段长度。具体结果如下:
以上就是递归查询的一些知识介绍了,自己可以动手实验一下,这个一般在面试中也经常会考察面试者,希望能帮助到大家~ |
 图片
图片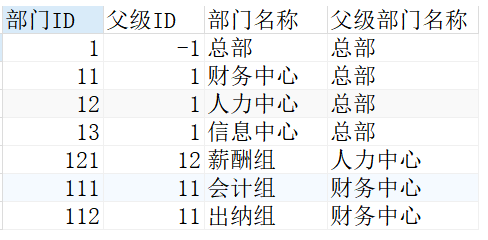 图片
图片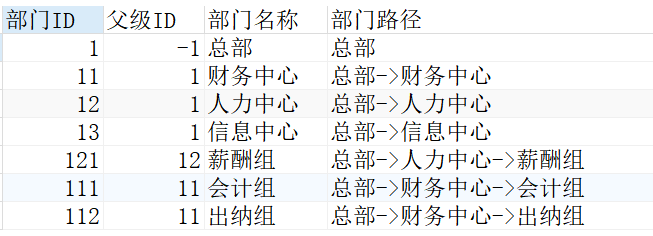 图片
图片