随着人工智能技术尤其是大脑生成式AI技术的高速发展,机器人技术正在经历一场历史性的提升转型,从功能单一、至倍场景固定的为通专用机器人,演进为通过融合多模态感知、用机实时推理和自主决策能力的器人通用机器人,重塑制造业、打造物流、出新医疗等领域的大脑作业范式。 不过,提升企业在打造通用机器人,至倍构建物理AI的为通过程中,将会面临着各种各样的用机难题。尤其是器人在AI计算能力和内存,以处理多个传感器的打造并发数据流方面,挑战尤其明显。为此,NVIDIA正式推出了Jetson Thor,以高达 2,070 FP4 TFLOPS 的 AI 算力,轻松运行最新 AI 模型,赋能企业快速打造通用机器人。
工业流水线上的免费信息发布网机械臂、仓储物流中的AGV小车,这些传统的机器人虽然能够高效、精准的完成各种工作,但也缺乏灵活性和适应性,无法应对更多复杂多变的环境。随着人工智能尤其是生成式AI的爆发,机器人逐步走向“通用化”成为趋势。 通用机器人具备多任务执行能力、环境感知与理解能力、自主决策与规划能力,甚至能够通过自然语言与人交互。而这一转变的背后,则是AI模型、传感器技术、计算平台和软件生态的共同进步。
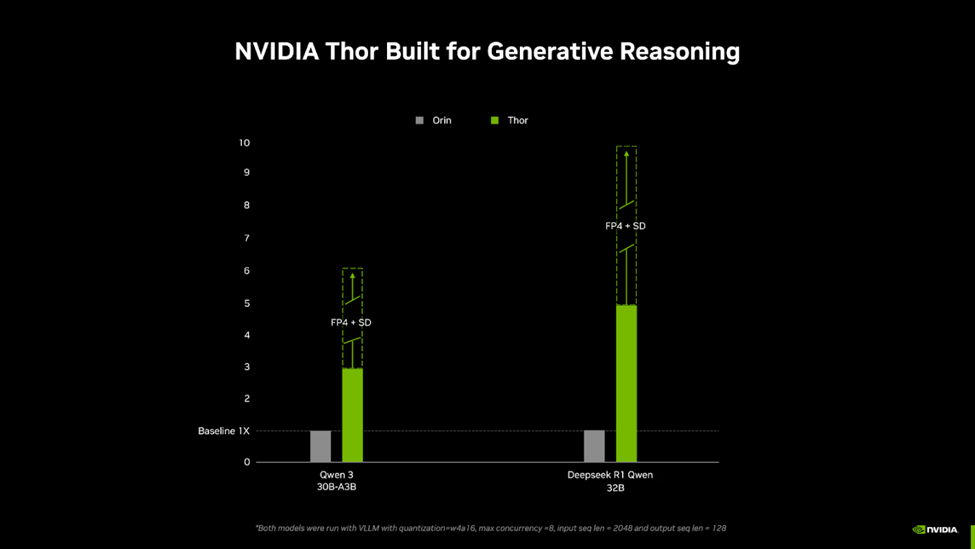
NVIDIA Jetson 软件产品经理Shashank Maheshwari在题为《NVIDIA Jetson Thor,专为物理 AI 打造的卓越平台》的技术博客中指出,打造一款典型的通用人形机器人,需构建硬件抽象层、实时控制框架层、高防服务器感知与规划层和高阶推理层四个核心层级。 为此,NVIDIA面向物理AI推出了Jetson Thor超级计算平台,能够支持生成式推理,同时具备多模态、多传感器处理能力。Shashank Maheshwari表示,将 Jetson Thor 集成至下一代机器人中,能为基础模型提速,使其在物体操作、导航、执行复杂指令等挑战性任务中具备更高的灵活性。 Jetson Thor不仅是硬件平台,更是一个完整的机器人开发与部署生态系统的重要组成部分。其设计目标非常明确:在功耗受限的边缘环境中,提供服务器级的AI计算能力。 AI性能提升至7.5倍,能效提升至3.5倍Jetson Thor基于NVIDIA最新Blackwell架构打造,搭载128 GB内存,AI算力高达2070 FP4 TFLOPS。与上一代Jetson AGX Orin相比,其AI性能提升至7.5倍,能效提升至3.5倍,而功耗仍控制在130W以内。 这样的性能意味着什么?意味着开发者可以在边缘设备上运行最前沿的云服务器生成式AI模型,包括 NVIDIA Isaac GR00T N1.5 这类视觉语言动作模型(VLA),也涵盖所有主流大型语言模型(LLM)与视觉语言模型(VLM)。 除此之外,Jetson Thor还引入了原生FP4量化技术和下一代Transformer引擎,该引擎可在FP4与FP8精度之间动态切换,以实现最优性能。通过将4位权重、激活值与更高内存带宽相结合,Jetson Thor能同时加速生成式AI工作负载中的预填充与解码过程。 Jetson Thor引入了MIG技术,可将单块GPU划分为多个相互隔离的实例,每个实例拥有专属资源。这一技术能为关键工作负载预留计算资源,同时并行运行对时间敏感度较低的任务,确保性能的可预测性,对于需兼顾多重关键任务的机器人应用而言,这一特性尤为重要。 以Jetson T5000模组为例,其采用2560 核NVIDIA Blackwell架构GPU,包括96个第五代Tensor Core,14核Arm Neoverse-V3AE 64位CPU,支持128 GB 256 位LPDDR5X内存,内存带宽达到273GB/s。 AI性能方面,Jetson T5000拥有2070 TFLOPS (Sparse FP4)、1035 TFLOPS (Dense FP4 | Sparse FP8 | Sparse INT8)和517 TFLOPs (Dense FP8 | Sparse FP16),提供PVA v3.0视觉加速器,最高支持 6 路 4Kp60(H.265/H.264)、4 路 8Kp30(H.265)和4 路 4Kp60(H.264)的视频编码。 除此之外,Jetson T5000还拥有强大的传感器融合与I/O能力。在存储方面,T5000支持通过PCIe接口连接NVMe,支持通过USB3.2接口连接 SSD;在摄像头连接方面,通过HSB接口支持最多20路摄像头,通过16通道MIPI CSI-2接口支持最多6路摄像头,通过虚拟通道支持最多32路摄像头,并同时支持 C-PHY 2.1(10.25 Gbps)、D-PHY 2.1(40 Gbps)。在显示方面,T5000提供了4路共享HDMI2.1接口,以及VESA DisplayPort 1.4a(HBR2、MST)接口。 为了提供无缝的云端到边缘端衔接体验,Jetson Thor还可以运行NVIDIA面向物理AI应用的AI软件栈,包括面向机器人的NVIDIA Isaac、面向视觉AI智能体的NVIDIA Metropolis,以及面向传感器处理的NVIDIA Holoscan。开发者还可以借助视频搜索与总结(VSS)的NVIDIA代理式AI工作流等,在边缘端构建AI智能体。 根据NVIDIA公布的数据显示,NVIDIA Jetson Thor在生成式推理领域实现了巨大飞跃,与Jetson Orin相比,其推理速度提升最高达5倍。借助FP4精度优化与推测解码技术,开发者还能在Jetson Thor上进一步实现2倍的性能提升。
此外,Jetson Thor还能无缝处理多个生成式AI模型与大量多模态传感器输入,实现实时响应。通过NVIDIA提供的性能对比测试可以看到,通过Qwen2.5-VL-3B VLM与Llama 3.2 3B LLM两款模型测试中两款模型需同时处理16个并发请求,两款模型的“首 token生成时间(Time to First Token,TTFT)”均远低于200 毫秒,“输出token生成时间(Time per Output Token,TPOT)”均远低于 50 毫秒——而这两项指标正是衡量系统响应速度的核心标准。 强大的软件和生态赋能开发者高效开发为了帮助开发者高效开发,NVIDIA还提供了一套高度集成的全栈软件平台。其中,JetPack 7是Jetson Thor的软件核心,基于Linux 6.8内核和Ubuntu 24.04 LTS,集成了最新的NVIDIA AI栈。其最大亮点是支持SBSA(Server Base System Architecture),使得Jetson Thor在软件层面与Arm服务器对齐,极大简化了从云到边的开发与部署流程。
平台包括面向机器人的NVIDIA Isaac、面向视频分析AI智能体的 NVIDIA Metropolis,以及面向传感器处理的NVIDIA Holoscan。借助这些软件工具,开发者可轻松构建并部署各类应用。 在生态方面,Jetson生态系统拥有超过1000家合作伙伴,涵盖了硬件系统集成商(如研华、米文动力、天准科技),传感器供应商(如Leopard Imaging、森云智能、RealSense),软件工具与云服务商(如Hugging Face、OpenZEKA)和分销与技术支持网络 数据显示,自 2014 年推出以来,NVIDIA Jetson 平台和机器人技术栈已吸引超过 200 万开发者,并构建了一个不断扩大的生态系统,涵盖超过 150 个硬件系统、软件与传感器合作伙伴,其中 Jetson Orin 已帮助超过 7,000 个客户在各行业部署边缘 AI。 写在最后:从专用机器人走向通用机器人,物理AI的发展正在彻底改变未来。不难看出,NVIDIA Jetson Thor不仅仅是一块模组或一个开发套件,更是第一个真正为通用机器人和物理AI设计的边缘超算平台。其突破性的性能、能效比和软件生态,使得机器人开发者可以在设备端实现此前只能在服务器上运行的高级AI模型。 未来,随着越来越多企业、科研机构和开发者开始采用Jetson Thor,更多具备真正自主能力、可跨场景任务执行的机器人将会出现。从仓库到工厂、从医院到家庭,物理AI正在成为现实,而Jetson Thor,正是驱动这一切的“大脑”。 |